TileRT
Ultra-Low-Latency LLM Inference
A revolutionary LLM engine that pushes the speed limits of the largest AI models—enabling the most powerful models to run in latency-critical scenarios.
$ pip install tilertLatest News
Try TileRT Online — Experience Ultra-Low-Latency Inference
We have launched tilert.ai, a hosted inference service powered by TileRT. Chat with state-of-the-art models like DeepSeek, GLM, etc., and experience real-time token generation.
Try it now at tilert.ai →v0.1.3 — Support GLM5 in TileRT
Support GLM5 in TileRT with up to 500+ TPS on NVIDIA B200.
v0.1.2 — Multi-token prediction (MTP)
Multi-Token Prediction (MTP) enabled in TileRT, reaching up to 600+ TPS for DeepSeek-V3.2-Exp on 8× NVIDIA B200.
v0.1.1 — Performance optimization
Achieved 1.35x further speedup (3 ~ 4x speedup over baseline), reaching 250+ TPS for DeepSeek-V3.2-Exp on 8× NVIDIA B200.
v0.1.0 — Initial public release
Initial public release, supporting DeepSeek-V3.2-Exp, achieving fastest inference speed among all available baselines.
Why TileRT?
Designed from the ground up for latency-critical LLM serving, and powered by advanced compiler techniques.
Ultra-Low Latency
Prioritizes responsiveness over throughput. Achieve millisecond-level time per output token (TPOT) for models with hundreds of billions of parameters.
First Tile-Level Runtime
Decomposes LLM models into fine-grained tile-level tasks and dynamically reschedules computation, I/O, and communication across multiple devices.
Compiler-Driven Technology
Leverages advanced compiler techniques to automatically minimize idle time and maximize hardware utilization through highly overlapped execution across GPUs.
No Compromise on Accuracy
Preserves full model quality and accuracy without any lossy optimizations such as quantization or distillation.
Scalable for Multi-GPU
Built for multi-device deployment, with dynamic scheduling that overlaps computation and communication.
High-Value Scenarios
TileRT is designed for empowering high-value AI scenarios, such as agents, vibe coding, trading, and real-time decision-making.
Performance Benchmark
TileRT demonstrates substantial improvements over existing inference systems on DeepSeek-V3.2-Exp.
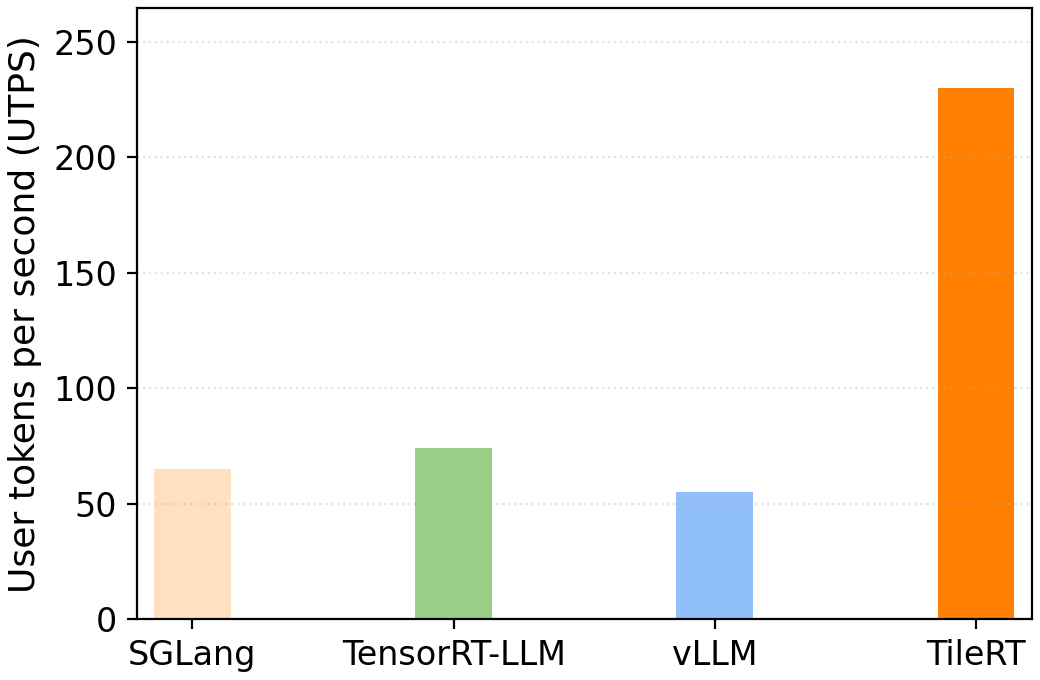
Evaluation setup: Batch size 1 · Input/Output sequence length: 1K/1K
SGLang v0.5.6 · TensorRT-LLM v1.2.0-rc5 · vLLM v0.13.0 · TileRT v0.1.1 · CUDA 12.9
8× NVIDIA B200 GPUs · DeepSeek-V3.2-Exp (no quantization/distillation)
Quick Start
Get TileRT up and running in minutes with Docker and pip.
Pull the Docker Image
Launch the Container
Install TileRT
Note: The current preview build supports the 8-GPU B200 setup. For the most reliable experience, we strongly recommend using the provided Docker image. See the GitHub repository for full documentation.
Ecosystem
TileRT is part of a growing ecosystem of compiler and runtime tools for AI workloads.
Supported Environment
Hardware and software requirements (more device support coming soon).
| Hardware | 8× NVIDIA B200 GPUs |
| OS | Linux x86_64 (Ubuntu 20.04+) |
| Python | 3.11 – 3.12 |
| CUDA | 12.9 |
| PyTorch | CUDA 12.8 / 12.9 wheels |